
The problem I am going to address in this article is not just limited to Hadoop Distributed File System (The storage system of BigData) , its prevalent across other platforms as well. When you have some data split up in a lot of smaller files, it puts unnecessary strain on the OS responsible for managing the storage as it has to keep track of all the small files instead of say one big file. Also since the small files are more likely to be scattered across the disk, any read or move operation has to seek all these numerous files first before it can do anything on it. Which is precisely why it’s much slower to copy a bunch of files rather than copying a single big file.
Yet the severity of the problem in case of Hadoop doesn’t simply end here and warrants a dedicated article on it !! Since the files themselves are replicated thrice and spread across the cluster of nodes making up the HDFS, things get complicated and messy as hadoop is designed to handle a small number of large files rather than large number of small files.
Here is a sample of the runtime improvement that can be achieved by tuning MapReduce to handle a large number of input files. I ran this job on Hadoop with Yarn running on my PC consisting of a quad core cpu with 8 gigs of ram. In case you don’t have a dev setup, you can check out my previous article – Hadoop on Windows which has a step by step tutorial for the same. You can also find the updated working code on my Git repo – https://github.com/kitark06/xWING
17 hours to 8 mins

The initial FileMerger.. which didn’t work as expected.
My motivation for writing a file merge program stemmed up because MapReduce was literally crawling at unacceptable speeds when running any analytical queries/jobs on small files. The initial version of FileMerger consisted of an out-of-the-box configuration for a simple merge operation using
- A mapper which similar to an Identity mapper, simply reads all the small files line by line and passes it to the reducer.
- A single reducer which writes all these small files into one large file.
- The input to this job is the WeatherDataSet which when uncompressed is a 450mb collection of around 44,000 files weighing around 2 kb each.
The execution time for this program was almost 17 to 18 hours.
A simple search reveals multiple articles written across the internet which suggest how to avoid ending up in a situation where you have multiple small files. They recommend altering the way output is written to HDFS and making sure such small files aren’t generated. These include routing the output and packing all the small files in a SequenceFile or HadoopArchive. But in my case (and anyone planning to use the WeatherDataSet) the data I got was already in this way and none of the articles mentioned a suitable way of dealing with this problem.
The below code shows my original version of FileMerge with most of the configurations set to default.
The Client
[java title=” ” highlight=”42″]
package com.kartikiyer.hadoop.filemerge;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class FileMerge extends Configured implements Tool
{
public static void main(String[] args) throws Exception
{
System.setProperty("hadoop.home.dir", "C:\winutils-master\hadoop-2.7.1");
System.setProperty("HADOOP_USER_NAME", "cloudera");
ToolRunner.run(new FileMerge(), args);
}
@Override
public int run(String[] args) throws Exception
{
Job job = Job.getInstance();
job.setJobName("FileMerger");
job.getConfiguration().set("mapreduce.app-submission.cross-platform", "true");
job.setJarByClass(FileMerge.class);
job.setMapperClass(FileMergeMapper.class);
job.setReducerClass(FileMergeReducer.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setNumReduceTasks(1);
Path in = new Path("/user/cloudera/Small_Files");
FileInputFormat.addInputPath(job, in);
FileSystem fs = FileSystem.get(job.getConfiguration());
Path out = new Path("/user/cloudera/mergedop");
if (fs.exists(out))
fs.delete(out, true);
FileOutputFormat.setOutputPath(job, out);
System.out.println("Starting job");
return job.waitForCompletion(true) ? 1 : 0;
}
}
[/java]
The Mapper
[java title=” “]
package com.kartikiyer.hadoop.filemerge;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FileMergeMapper extends Mapper<LongWritable, Text, LongWritable , Text>
{
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
{
String line = value.toString();
if (line.length() > 50)
{
context.write(key,value);
}
}
}
[/java]
The Reducer
[java title=” “]
package com.kartikiyer.hadoop.filemerge;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FileMergeReducer extends Reducer<LongWritable, Text, Text, NullWritable>
{
@Override
public void reduce(LongWritable key, Iterable<Text> vals, Context context) throws IOException, InterruptedException
{
for(Text value : vals)
{
context.write(value, NullWritable.get());
}
}
}
[/java]
The fault in our.. InputSplits
The way Hadoop Framework works is that when a client submits a job,
- It validates the input directory and then calculates the input splits for all the files in that directory before the program’s is allocated a container (resources) and executed.
- The inputSplit consists of information about the file like its locations in the cluster.
(Files in HDFS are made up of parts as they split into chunks and each chunk is replicated thrice and stored across the cluster in a distributed fashion). - If the file is smaller than the HDFS block size (128mb default in Cloudera) one inputSplit is made for that file.
- If the file is larger than the blockSize of HDFS, then multiple inputSplits are made for that file
(Eg a 200 mb file will be split like 128 + 72) - This is done for each file in the input directory specified in the job.
- TaskIDs (Map & Reduce tasks) are generated and assigned for each inputSplit.
- A Map<TaskID,inputSplit> Object is created which has entries as for each TaskID and their corresponding inputSplit.
So when we use TextInputFormat as the input loader class for an input directory with 44,000 files, as each file is significantly smaller than the HDFS block size, 44k inputSplits are generated and for each split, a separate JVM is spawned . Thus 44,000 JVMs were spawned and destroyed repeatedly in the lifetime of the application. This added massive overhead and slowed things unnecessarily and the job lasted over 17 hours.
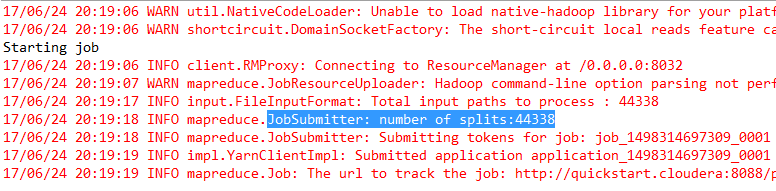
Using CombineText InputFormat to reduce InputSplits
Having identified the cause of the problem, I searched for an alternative way to handle the creation of InputSplits and found the solution in the form of the CombinedTextInputFormat. This input loader class as the name suggests, packs all input directory files residing in a single rack to one huge input split chunk and gives it to the mapper as input. This would also mean that in its default behavior, only one mapper per rack will be spawned, which will be given the entire input chunk to process.
This is not ideal as by creating only one mapper per rack, the parallelism of Hadoop is lost as the job effectively becomes sequential in nature. To remedy this, I modified the default behavior of the CombinedTextInputFormat class by subclassing it with my own class called Converger and modifying the setMaxSplitSize to 128mb. I then used my class as the input loader class.
And using it reduced the number of inputSplits from 44,000 to just 4 and the runtime reduced to 8mins.

You can check my code below.
The Updated Client
[java title=” ” highlight=”41″]
package com.kartikiyer.hadoop.filemerge;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class FileMerge extends Configured implements Tool
{
public static void main(String[] args) throws Exception
{
System.setProperty("hadoop.home.dir", "C:\winutils-master\hadoop-2.7.1");
System.setProperty("HADOOP_USER_NAME", "cloudera");
ToolRunner.run(new FileMerge(), args);
}
@Override
public int run(String[] args) throws Exception
{
Job job = Job.getInstance();
job.setJobName("FileMerger");
job.getConfiguration().set("mapreduce.app-submission.cross-platform", "true");
job.setJarByClass(FileMerge.class);
job.setMapperClass(FileMergeMapper.class);
job.setReducerClass(FileMergeReducer.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setInputFormatClass(Converger.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setNumReduceTasks(1);
Path in = new Path("/user/cloudera/Small_Files");
FileInputFormat.addInputPath(job, in);
FileSystem fs = FileSystem.get(job.getConfiguration());
Path out = new Path("/user/cloudera/mergedop");
if (fs.exists(out))
fs.delete(out, true);
FileOutputFormat.setOutputPath(job, out);
System.out.println("Starting job");
return job.waitForCompletion(true) ? 1 : 0;
}
}
[/java]
The Converger – Subclassed CombineTextInputFormat
[java title=” ” highlight=”10″]
package com.kartikiyer.hadoop.filemerge;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
public class Converger extends CombineTextInputFormat
{
public Converger()
{
// setting block size to 128mb which is the Cloudera default HDFS size
this.setMaxSplitSize(134217728L);
}
}
[/java]
JVM Reuse.. very close to the solution.
Since the problem here was the insane amount of JVMs created and launched, reusing JVMs in between input splits would technically also solve the problem.
We can set the number of times JVM is reused by the mapreduce.job.jvm.numtasks and setting it to -1 (for unlimited reuse throughout the Job lifecycle)
job.getConfiguration().set(“mapreduce.job.jvm.numtasks”, “-1”);
Running this version of the program on a production grade server deployed on Google Cloud, I was able to reduce the runtime from 1 hour to 12 mins.
The only issue here is that this is deprecated & only works on the earlier versions of Hadoop without a YARN based cluster.


2 responses to “Small files.. Big problem !! – Using CombineTextInputFormat to optimize MapReduce & handle large number of small input files.”
[…] Hopefully my argument has made it clear why it’s imperative to store the streaming messages even if they are processed seemingly instantaneously. Having to process a stream of continuous events which would usually be unending, we need a storage system which can allow continuous reads and writes in a simultaneous and concurrent fashion. Writing the messages on files on top of HDFS won’t solve our purpose as we also want to process the messages simultaneously, which HDFS wont allow. Remember, the inputsplits of any hadoop job is defined at job creation and thus would only include the data blocks [or in our case, messages] present at the time at which the streaming job was started, and would ignore all the subsequent messages which were written to the files after the job was started. I delved into input splits in detail in my previous post, which can be read by clicking this link. […]
LikeLike
[…] and these tasks form the execution units for that Job. You can check out my previous article Small files.. Big problem – where I wrote about how the framework generates these tasks in detail and an […]
LikeLike